
 Okapi Shared Help
Okapi Shared Help
Tutorial 2 - Translating with Rainbow and OmegaT
- Introduction
- Preparation
- Translation
- Post-Processing
|
|
|
- Introduction |
|
This tutorial provides a step-by-step guide on how to use the Text Extraction and the Text Merging utilities from Rainbow to pre- and post-process files to be translated using OmegaT, one of the free translation tools available in the open source community.
Note that tutorials may not be updated as frequently as the Okapi tools, so some options and screen shots may not reflect the latest versions of the tools and components available.
Note also that this documentation may not be always synchronized with OmegaT releases, so you may find differences between the descriptions given here and the latest version of the application.
This tutorial does no go into deep details about the different options of the Text Extraction utility, for more details see the Tutorial 1.
Requirements:
In this tutorial we have two files to translate: one is a WinHelp table of content (.cnt) file, the other is a PO file. We want to translate them using OmegaT. We can use the Okapi Text Extraction and Text Merging utilities to pre- and post-process the files, and work, between the two processes, in an OmegaT project.
The pre-processing is done as follow:
Start Rainbow.
If you have a project loaded automatically, you need to reset all the project settings. To do this, select the command New from the File menu (or press Ctrl+N). Now you should have an empty project.
To add files to the first input file list: Go to the Input List 1 tab if you are not yet there, then select the command Add from the Input menu (or press Insert). A dialog box titled Add Files to Input List 1 should open.
Select the files to
insert into the input file list. In this example we are using all the files located in the folder:
"C:\Program Files\Okapi\Shared\Samples\T02".
Highlight all the files in that folder and click Open.
Now you should have the files listed in Rainbow:

There
are other ways to list input files. You can select the files (or the
folders) in Windows Explorer and drag-and-drop them over Rainbow. You can
also select the command Add Multiple from the Input
menu and select a set of files based on a pattern like *.txt, etc.
Now that we have our input files listed we need to make sure each one is associated correctly with a filter. In this case Rainbow has recognized both file formats and has associated the proper filter to each one:
WinHelpTest01.cnt is associated with
okf_script@WinHelp_CNTGandalfPro.po is associated to okf_poInfo01.xml is associated to okf_xmlThis is fine for this example. If needed you could change the filter association using the Properties command in the Input menu.
Go to the Options tab of Rainbow. This is where input and output languages and encodings are defined.
In this example, the input language is English. And you can set the target language to whatever language you want.
For the encoding, the WinHelp CNT file is in windows-1252. The PO file and the XML document have an encoding declaration that will be automatically recognized by the filter (so you don't have to worry about it).

Along with languages we need to define the default encodings for the input and output files. Select the proper Windows encoding for the target language that you have selected. For example Windows-1252 for French. In the case of the PO file and the XML document, the internal encoding declaration will be automatically updated when merging back the file.
Now is time to do the extraction. Select Text Extraction from the Utilities menu. This opens the Text Extraction Utility dialog box.
Move to the Format tab. This is where we specify the way the output files are to be generated.
Select the "XLIFF for OmegaT" option.

Move to the Options tab.
Make sure the option Create a TMX output file with any pre-translated entries found is set. This will ensure that if one of the input file is bilingual (like the PO file) if there are entries already translated, they will be put in a TMX translation memory that you will be able to re-use with OmegaT.

The TMX file generated will go in the tm folder of the OmegaT
project.
Move to the Package tab.
Set the option Create an OmegaT project file. This will select automatically other options necessary for the project in this tab.
Enter the path where you want the OmegaT project to be created. The Package name is the name of the project.

Now that we have all parameters defined, we are finally ready to run the Text Extraction utility.
Click Execute.
If the folders you have specified for the output exist already, you will be prompted to select what you want to do with the files possibly there already. The following dialog box will pop up:
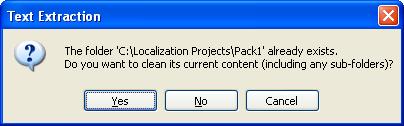
Click Yes to delete all files and sub-folders in the specified output folder. Note that the utility will not be able to remove files that are still open with other applications or sub-folders that are activated. If this happens, you will get a warning message in the Log.
Click No to not delete any existing file or sub-folders. However, any output file generated during this process will overwrite any existing file with the same path.
Click Cancel to not delete anything and stop the process.
For this tutorial, if prompted, select Yes.
All warning and error messages are stored in Log window. At the end of the process, if there was no error and no warning the Log window is closed automatically. If any error or warning occurs, the Log window remains opened after the process is done.
When the process is completed, you can open the folder where the output files were generated by selecting the command Open Last Output Folder from the Utilities menu (or press Ctrl+L). This will open the project folder.

The project has the following folders:
Original folder contains the two original source
files. they will be used after translation for merging.source folder contains the two prepared files in
tab-delimited format. These are the files to translate with OmegaT._Merge.bat and
_Merge.rbp. These files will be used to merge the
translated files. This folder is also where OmegaT will generate the
translated files.To translate the files.
Start OmegaT.
Select the Open command from the Project menu. Select
the project we have just created and open it. At this point OmegaT will get the
list of the files in the source folder and parse them. The files are loaded in the program and the Project Files
window is opened.
Select the file you want to work on and start translating.

<xN/> and <gN>...</gN>
codes inside your text. You can move them around but not delete any or
add any. You can use OmegaT's Validate Tags command to
check if all codes are properly set.You can translate the entries of the file as you would do for any other file.
Once the files are translated, you can do the post-process step.
In OmegaT, select the Create Target Documents from the
Project menu. This creates the translated tab-delimited table files in
the target folder.
You can close OmegaT.
In Windows Explorer, go to the target folder (in this example:
C:\Localization Projects\Pack1\target).
Double-click the _Merge.bat file. This batch file runs Rainbow
Text Merging utility
with the settings generated when you did the extraction and saved in the _Merge.rbp
file.
If one or more errors occur Rainbow stays open and the Log window is displayed.
If no error occur, Rainbow runs and closes itself...

...and the translated merged files are saved in the same target folder (the
files without the extra .xlf extensions).
You are done.